AI Presence Score
Your headline number. One value from 0 to 100 that combines four things AI engines care about: do they see you, do they like you, do they trust your category footprint, and are your sources citable. After a fix ships, this is the number you’re trying to move.
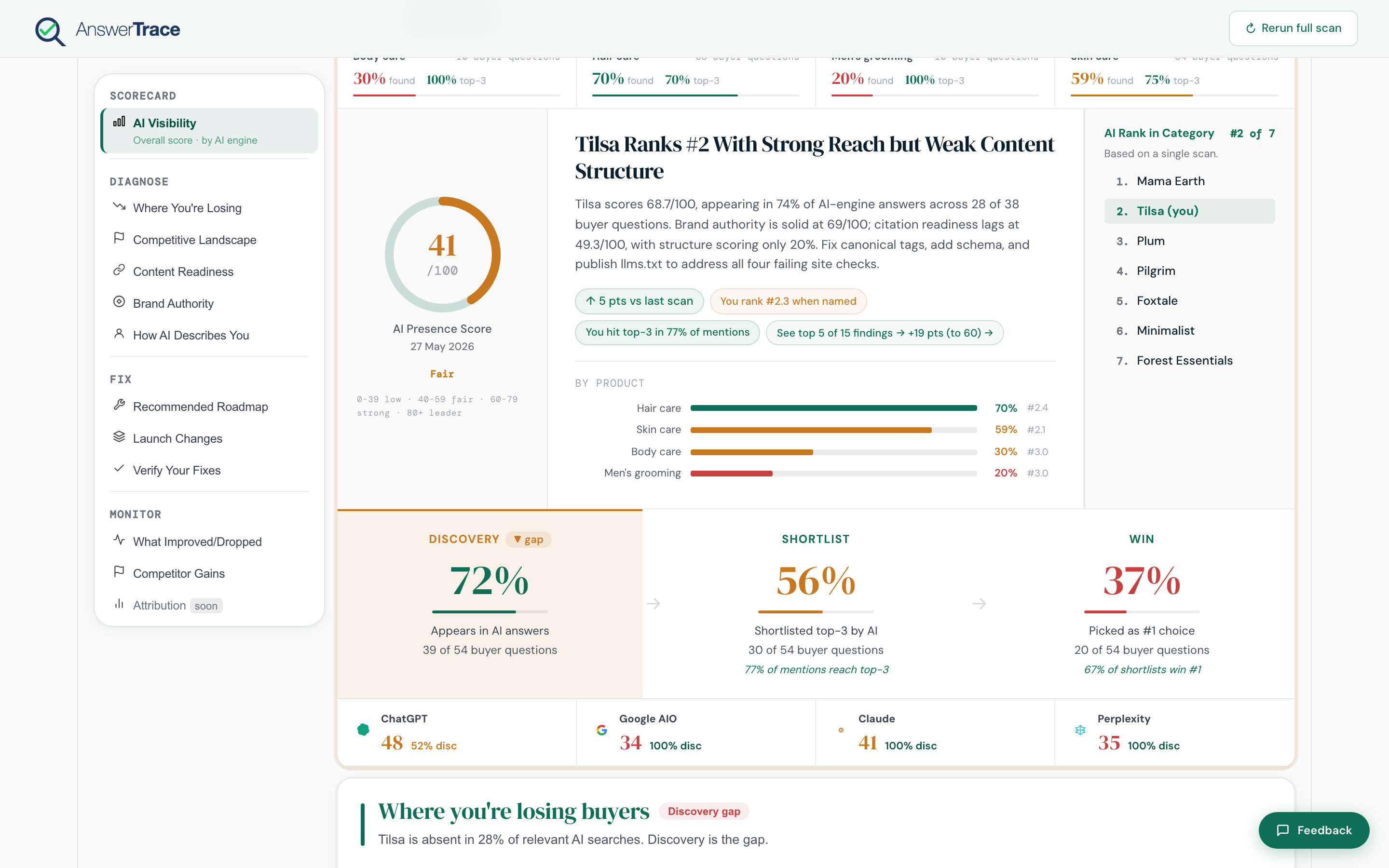
How the score is built
The headline score is a weighted blend of four sub-scores:
| Component | Weight | What it measures |
|---|---|---|
| Visibility | 35% | How often you appear and where, across every prompt and engine |
| Brand authority | 25% | Wikipedia, Wikidata, G2, Reddit, G2 rating, press / newsroom |
| Sentiment | 20% | Positive / neutral / negative tone of the sentences that name you |
| Citation readiness | 20% | Whether your owned surfaces (schema, llms.txt, FAQ, canonical, robots) give engines clean sources |
Each component is itself normalized to 0 to 100. Visibility is the most-weighted piece because it answers the basic question (am I named at all), but the other three matter for how an engine names you and whether it will pick you again next week.
The legend bands in the report read:
- Leader, 80 and up, you’re the default answer for your category
- Strong, 60 to 79, named consistently, room to climb on a few engines
- Fair, 40 to 59, named some of the time, several gaps to close
- Low, below 40, missing from most answers
The three-stage funnel
The funnel directly below the score is three bars, not four. It shows how a prompt-shaped audience narrows down to a winner:
- Discovery, your brand appears in the AI answer at all
- Shortlist, your brand is in the top three brands named
- Win, your brand is the #1 choice the AI picks
A healthy funnel narrows gradually. A funnel that crashes from 80% Discovery to 5% Shortlist means engines know you exist but don’t consider you a serious option. That’s a positioning fix, not a visibility fix.
The four-bar “Buyer questions tested → Mentioned → Shortlisted → Won” funnel is a different view, and it lives in Where you’re losing, not here.
The engine breakdown
The row below the funnel splits the score across ChatGPT, Google AIO, Claude, and Perplexity. Engines are gated by plan: ChatGPT on Free, plus Google AIO on Starter, plus Claude on Growth, plus Perplexity on Pro. Pro is the only plan that shows all four.
Common patterns:
- High on ChatGPT, low on Google AIO, you have chat-style coverage but no search citations. Fix the on-site SEO and llms.txt.
- High on Google AIO, low on Claude, Google has indexed you but Anthropic hasn’t picked you up. Push for third-party authority (Wikipedia, review sites).
- Low on Perplexity, you don’t have enough citable sources. Build press and review surface area.
What this means for you
The score is the diagnostic. The funnel tells you which stage is broken. The engine row tells you where to spend effort first. The fix list in Recommended roadmap is built from the same data and tells you which action moves the score for the least effort.